Part 2: Log file compression with SQLite + benchmark
Watch out! You're reading a series of articles
- Part 1: Log file compression with Gzip and Zstandard + benchmark
This is the first part of a series of articles diving into log files compression techniques.
- (currently reading) Part 2: Log file compression with SQLite + benchmark
The second part utilizes SQLite as an embeddable storage that not only provides querying capaibilites but also is able to compress the logs itself.
- Part 3: Log file compression with Zstandard VFS in SQLite + benchmark
The third part dives deeper into compression capabilities of SQLite using Zstandard compression algorithm.
- Part 4: Log file compression with Zstandard selective column in SQLite
The fourth part explores database level compression of specific columns within SQLite.
You can find the script that was used to seed the database with data, perform compression and run benchmarks here.
In this part of the series, we're going to take one step further and insert the log lines into SQLite database.
What is SQLite?
SQLite is a lightweight, serverless, self-contained relational database management system (RDBMS) that stores data in a single file. It’s widely used in applications like mobile apps, embedded systems, and browsers for local storage.
We're going to approach the problem from two sides: inserting log lines into a table with columns and also import a raw JSON into table with a single TEXT column. SQLite supports querying JSON with a specific syntax: col_name->>json_poperty and allows us to use it in select, where and group by clauses.
First, let me describe the settings we're running the SQLite with:
sql
PRAGMA journal_mode = OFF;
PRAGMA busy_timeout = 5000;
PRAGMA synchronous = OFF;
PRAGMA cache_size = 1000000000;
PRAGMA foreign_keys = false;
PRAGMA temp_store = memory;
PRAGMA page_size = 16384;These setting are mostly directed towards fast insert times (do not use them for production setting) allowing to achieve a rang of 100k - 150k inserts per second (in batches of 150 rows using prepared statements).
Inserting logs into SQLite table with columns per field
sql
CREATE TABLE IF NOT EXISTS nginx_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
time_local TEXT,
remote_addr TEXT,
request TEXT,
status INTEGER,
body_bytes_sent INTEGER,
http_referer TEXT,
http_user_agent TEXT,
request_time TEXT,
upstream_response_time TEXT,
upstream_addr TEXT,
upstream_status INTEGER
);Inserting the data into SQLite. I achieved around 140k inserts per seconds using prepared statements and bulking (150 rows in bulk). I also tweaked SQLite to increase the insert performance.
This is the size of the database file size, and the same file after gzipping. You can see we get similar results (raw TXT file takes 232MB and gzipped version is 58MB) compared to compressing raw data files in the previous post.
bash
242M nginx_logs_columns.db
70M nginx_logs_columns.db.gzThis is not bad as we just go an ability for a very advanced querying over our logs at an expense of fixed schema. This may not be very useful if you're dealing with lots of logs from different systems or modules where each line could be of a different format. However, if you know the schema, you can definitely leverage SQLite to store the logs (and even compress it!).
Adding indexes to a table
Now let's add some indexes, for the purpose of the benchmar we're going to add 2 indexes:
- Index on
statuscolumn - Index on
time_localfield
This is dictated by the fact that logs are always queried by time and optionally additional field to limit the scope of the query. For webserver logs, a common queries are run on status column to detect errors.
sql
CREATE INDEX IF NOT EXISTS status_idx ON nginx_logs (status);
CREATE INDEX IF NOT EXISTS time_local_idx ON nginx_logs (time_local);This is the size of the database file with 2 indexes. The size increased by around 40Mb, but thanks to that cost, we unlocked very fast queries based on 2 columns.
bash
287M nginx_logs_columns.dbInserting logs as JSON into SQLite table
Next, we took onto inserting a JSON into a SQLite column like this:
sql
CREATE TABLE IF NOT EXISTS nginx_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
json_log TEXT
);The space taken by this approach is similar to the size of the JSON file, which makes sense. SQLite was not able to optimize it in any way as it treats the JSON as a normal string.
bash
442M nginx_logs_json.dbSQLite JSONB format
SQLite supports JSONB format and promises between 5% - 10% size reduction in size and half of the CPU cycles needed to parse it when querying. I didn't use this format during this benchmark as I only learned about this feature later. I did some preliminary tests with it, however the results were not promising so I decided not to pursuit and redo the work.
Adding indexes to a table with JSON
Adding indexes on JSON in SQLite is a bit more cumbersome. SQLite supports querying fields that contain a valid JSON string however it does not support indexing those fields. There is however a solution that allows to bypass that constraint: create a virtual column based on JSON field and setup an index on that column.
The ALTER TABLE query will look the following:
sql
ALTER TABLE nginx_logs
ADD column status INTEGER
AS (json_extract(json_log, '$.status'));
ALTER TABLE nginx_logs
ADD column time_local TEXT
AS (json_extract(json_log, '$.time_local'));
CREATE INDEX IF NOT EXISTS status_idx
ON nginx_logs (status);
CREATE INDEX IF NOT EXISTS time_local_idx
ON nginx_logs (time_local);There is also one other option which we didn't tried, it's called Index On Expressions and allows to be directly formed on an expression involving a table column.
The index could look like this:
sql
CREATE INDEX status_idx ON nginx_logs (json_extract(json_log, '$.status'));We didn't pursue this solution, however there could be some potential gains in regards to storage taken as there is no need to create an additional column which will obviously take space.
The indexed DB file with JSON took 476Mb
bash
476M nginx_logs_json.dbBelow is the chart comparing the sizes of each file:
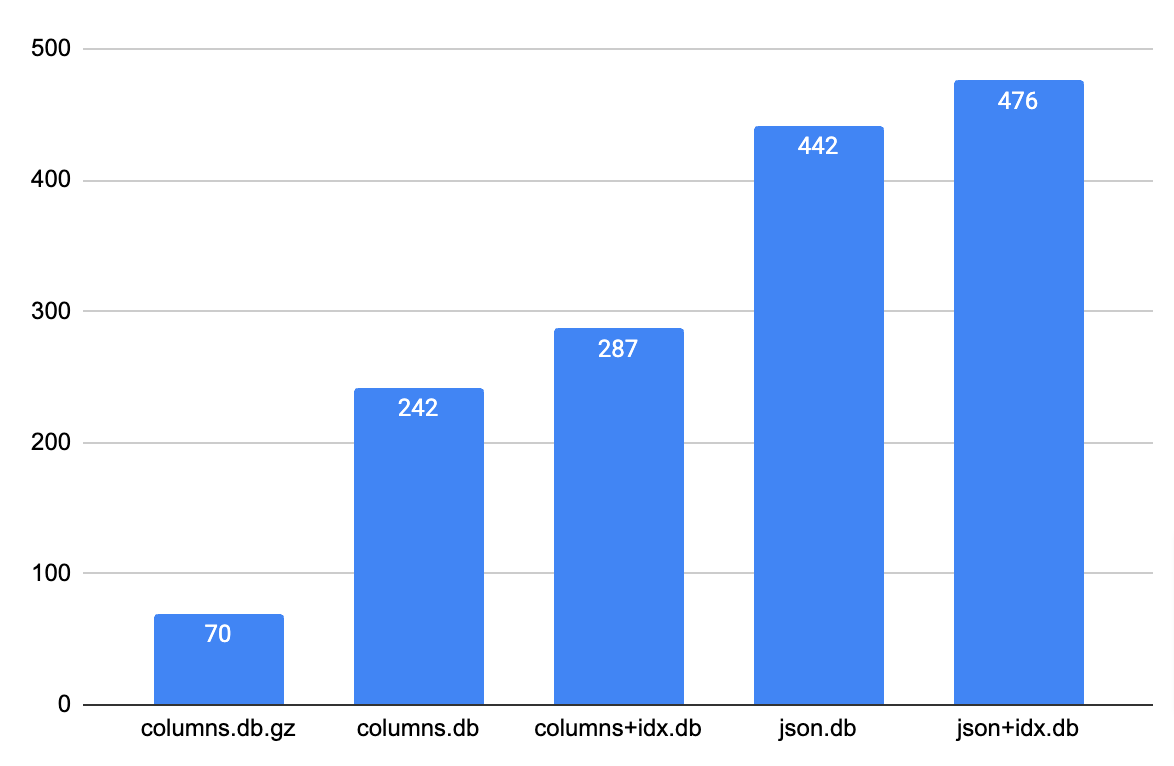
Benchmark - query SQLite table
Now it's time to run some queries. I decided to focus the benchmarks around 4 queries:
sql
select count(*) from nginx_logs;
select count(*) from nginx_logs where status = 200;
select status, count(*) from nginx_logs group by status;
select status, count(*) from nginx_logs where status = 200 group by status;Each query was run 5 times in sequence and average values were computed. Here are the results:
Column table, no indexes
Query 1: 36ms
Query 2: 57ms
Query 3: 172ms
Query 4: 58msColumn table + indexes
Query 1: 10.747ms
Query 2: 2.093ms
Query 3: 3.522ms
Query 4: 4.138msAs expected, we've experience a massive speed improvement with the queries.
Benchmark - query SQLite table containing JSON
Then we run the same queries on a table with JSON.
JSON table, no indexes
Query 1: 923ms
Query 2: 1.41s
Query 3: 2.55s
Query 4: 1.46sJSON table + indexes
Query 1: 316ms
Query 2: 13.81ms
Query 3: 973ms
Query 4: 1.05sThe results plotted on a chart
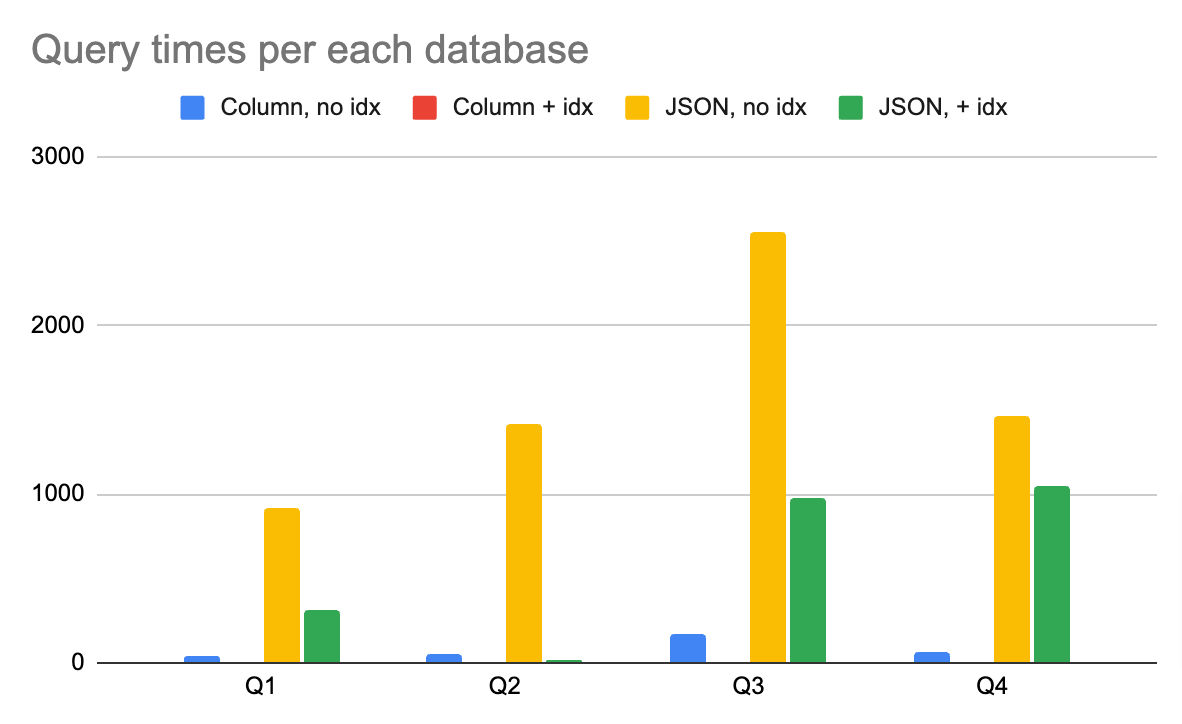
We can see that the indexes helped speeding up the queries which is not a surprise. This is coming at a cost however: the DB file size grows.
Also the JSON query times are not attractive when compared to the space the uncompressed file takes. I would assume that using jq or grep/awk would be even faster on these raw files than on SQLite.
Now, let's head onto the next part of the series, this is where it starts getting interesting.
Watch out! You're reading a series of articles
- Part 1: Log file compression with Gzip and Zstandard + benchmark
This is the first part of a series of articles diving into log files compression techniques.
- (currently reading) Part 2: Log file compression with SQLite + benchmark
The second part utilizes SQLite as an embeddable storage that not only provides querying capaibilites but also is able to compress the logs itself.
- Part 3: Log file compression with Zstandard VFS in SQLite + benchmark
The third part dives deeper into compression capabilities of SQLite using Zstandard compression algorithm.
- Part 4: Log file compression with Zstandard selective column in SQLite
The fourth part explores database level compression of specific columns within SQLite.
You can find the script that was used to seed the database with data, perform compression and run benchmarks here.