How Not To: Logging (use logs to make $$$, by not losing it)
Intro
In the dynamic realm of software engineering, mastering the art of logging can be the difference between prosperity and chaos. Yet, many engineers unknowingly stumble into pitfalls that jeopardize the very foundation of their applications.
This guide unveils the common missteps, empowering you to leverage the true potential of logs, ensuring they become a vital tool in your arsenal rather than a source of unforeseen headaches.
"We don't care about the costs until we do"
Before you dive into this lecture, let me introduce you to a case of a $65M bill for a DataDog subscription that happened to Coinbase. Of course, Coinbase was (still is?) growing like crazy and we all know the mantra "move fast and break things", and it's all great and nice when the revenue dollars are flowing through the doors and windows. This is when the bet is on: we don't care about the costs as long as we're growing fast or faster than those (costs).
Planning fallacy
It's a cognitive bias in which individuals tend to underestimate the time, costs, and risks of future actions and overestimate the benefits. It reflects a tendency to be overly optimistic and not adequately consider potential challenges or unforeseen circumstances. (Wiki)
The plot twist
Happens, usually suddenly, when the organization (or a person) starts to feel the pain of the spending because the cure for it disappears (read: we no longer have revenues that would justify the spending). What do you do then? How do you reduce that enormous bill without stopping the shop for weeks or months?
Coinbase case
Allegedly, in 2021 Coinbase spent $65M on DataDog. That's a huge pile of money. I don't challenge the need, however, I would argue whether that bill can be smaller considering that it's most likely a large portion of their Infrastructure tools spend. Check the history yourself:
https://thenewstack.io/datadogs-65m-bill-and-why-developers-should-care/
https://twitter.com/TurnerNovak/status/1654577231937544192
https://blog.pragmaticengineer.com/datadog-65m-year-customer-mystery/
What's the takeaway? How much smaller the bill could be if logs were to be placed more carefully? We'll never know, but one thing for sure, the bill could be significantly lower.
Why is that?
Observability tools & costs
Here's an interesting comment from the Web. 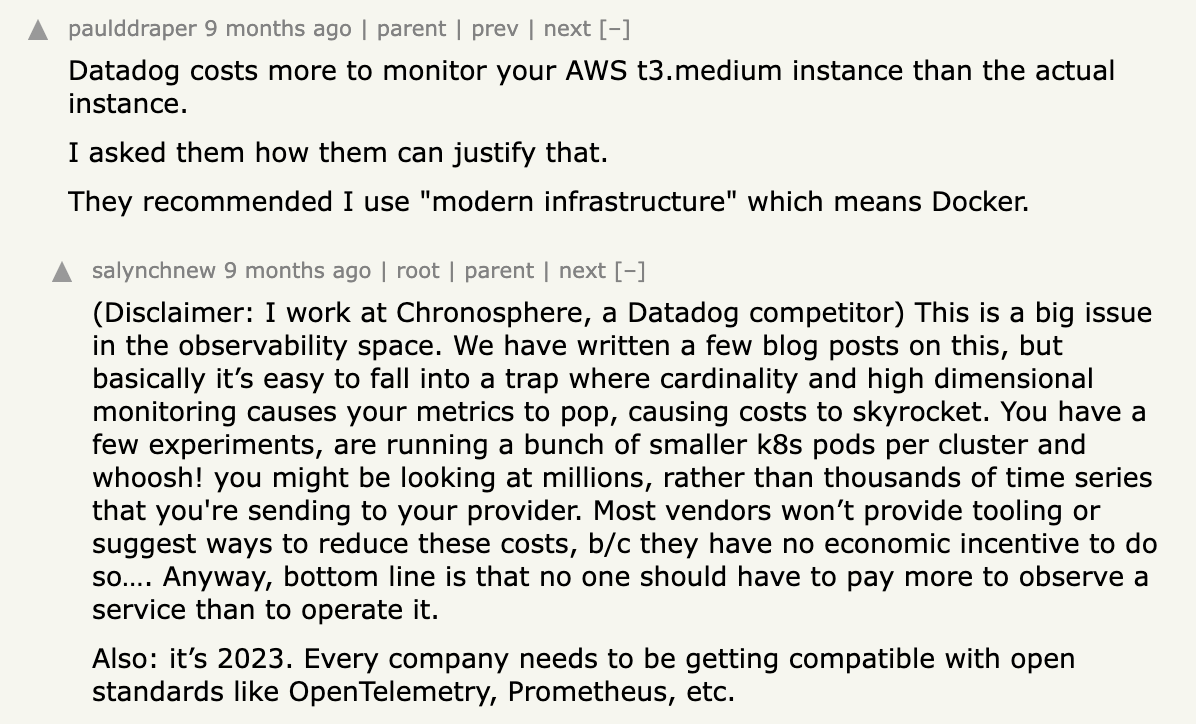
People: Datadog costs more to monitor your AWS t3.medium instance than the actual instance.
Observability tools: (...) no one should have to pay more to observe a service than to operate it.
Using observability tools, you trade convenience and thinking for an inflated observability bill. It's easy to put a bunch of logging statements with whatever** content and then sink them into a 3rd party tool. You don't see costs of logs when you're placing them in the code.
How to avoid big bills? Just avoid big spends
It's this simple (and a bit naive, but it works), below we're sharing a few advice and tricks on how to avoid inflated observability tool bills. You can do that by avoiding or fixing a situation that created this bill.
Logs that will inflate your bill noticeably
Overloading Logs with Information
On the flip side, providing too much information in every log entry can lead to information overload. Engineers may struggle to find relevant details amidst the noise, making it harder to pinpoint important events.
Log spam
Excessive logging of trivial or repetitive information can create unnecessary noise and hinder identification of important events. Implementing filtering mechanisms can help eliminate unnecessary log entries and maintain focus on critical events.
What is often a case if very trivial, leaving log level set to the development environment. Usually during development, we require more verbose logging (dev, debug level). Keeping those on production will heavily inflate your costs, we've been there, done that.
Logs that can cost you (or your company) a lot of money if things go sideways
Ignoring Security Implications
Neglecting to log security-related events or failing to properly secure log files can have serious consequences. Security incidents may go unnoticed, or sensitive information may be exposed if logs are not handled securely.
Hardcoded Sensitive Information
Embedding sensitive data such as passwords or API keys directly into log messages is a significant security risk. This information can be exposed if logs are mishandled or accessed by unauthorized parties.
This one is especially tricky, imagine having a config injection at runtime in your infrastructure, one that does not require any manual handling so that database credentials can be safely used... Then a log message with these credentials that gets sent to an observability tool...
Imagine the observability tool getting hacked and logs being breached. You are still responsible for the data of your users.
Logs that will cost you time (therefore money)
Insufficient Detail
Failing to provide enough information in log messages can hinder debugging efforts. Vague or overly general log messages make it challenging to identify the root cause of issues when they occur.
python
def process_data(data):
# Incomplete log message
logging.error("Data processing failed.")
# Actual processing logicThanks, that was really helpful.
Misleading or inaccurate logs
Logs should accurately reflect the state of the system, avoiding misleading information that can lead to misdiagnosis and wasted time during troubleshooting.
python
def divide_numbers(a, b):
try:
result = a / b
logging.info(f"Division successful: Result - {result}")
except ZeroDivisionError:
logging.error("Division by zero occurred.")Confusing terminology
Using too much technical jargon (tribal language) or unclear language in logs can make them difficult to understand for individuals outside the immediate development team. Opting for clear and concise language can improve accessibility and facilitate collaboration.
python
def calculate_metrics():
# Unclear log message with technical jargon
logging.info("Executing performance metric computations.")
# Actual calculation logicWhat does that even mean?!
Inconsistent Formatting
Inconsistency in log formats across different components or modules can complicate log analysis. Engineers should establish and adhere to a standardized log format to ensure uniformity and ease of parsing. The more uniform the format across the stack/organization the better, even a simple thing like JSON can be tricky. Imagine a ts field with a timestamp: one with UNIX time, the second UNIX micro milliseconds.
Lack of Contextual Information
Failing to include contextual information like timestamps, user IDs, or relevant environmental details makes it difficult to understand when and where events occurred. This context is crucial for effective log analysis.
python
def process_request(request):
# Insufficient contextual information in the log
logging.debug("Processing request.")
# Actual request processing logicNot Considering Log Rotation
Overlooking log rotation practices can lead to log files consuming excessive disk space. Proper log rotation policies should be in place to prevent issues related to storage constraints.
python
def log_large_data():
# Log entry without considering rotation
logging.info("Large data: " + "*" * 1000000)
# Actual processing logicOverlooking Log Levels
Incorrectly assigning log levels (info, warning, error, etc.) can impact the severity assigned to events. This may result in critical issues being overlooked or less critical events being treated as emergencies.
python
def log_critical_issue():
# Incorrectly assigning log level
logging.info("Critical issue occurred.")
# Actual handling of critical issueIgnoring Performance Impact
Intensive logging, especially in production environments, can impact application performance. Engineers should be mindful of the performance implications of logging and balance the need for information with system resources.
python
def log_in_loop():
for i in range(100000):
# Intensive logging in a loop
logging.debug(f"Processing item {i}")
# Actual processing logicFailing to Monitor Log Files
Establishing a proactive log monitoring system is essential. Ignoring logs and failing to set up alerts for critical events may result in delayed response to issues or security incidents.
Forgetting to Update Logs with Code Changes
When code evolves, log messages should evolve with it. Forgetting to update log messages to reflect changes in functionality or to include new relevant details can lead to confusion during troubleshooting.
Not Planning for Scalability
As applications scale, logging can become a bottleneck if not designed for scalability. Engineers should consider distributed logging solutions and implement log aggregation to handle increased log volumes.
Lack of Automation
Manual log analysis: Manually analyzing large volumes of logs can be time-consuming and error-prone. Implementing automated tools and scripts can streamline log analysis, identify patterns, and trigger alerts for critical events, allowing engineers to focus on higher-level tasks and respond to issues more efficiently.
Have you considered Logdy? We can help you with that
Why does it even matter?
The bigger the engineering organization the more important your log messages will be for the two above reasons mentioned: money & time. Bigger engineering organizations work like distributed systems in a way, it's impossible to keep the knowledge centralized, so naturally it will flow from one place to another. Having an intuitive, clear "logging" culture makes the job easier definitely.
Of course, you can get away with a lot of things mentioned above if you are a solo developer or your team is small. You can also get away with things if you handle low traffic volume (how much is that really?). However, at some point, you will stumble upon a situation where you have to make a choice. Then it's good to know what to avoid.