Part 1: Log file compression with Gzip and Zstandard + benchmark
Watch out! You're reading a series of articles
- (currently reading) Part 1: Log file compression with Gzip and Zstandard + benchmark
This is the first part of a series of articles diving into log files compression techniques.
- Part 2: Log file compression with SQLite + benchmark
The second part utilizes SQLite as an embeddable storage that not only provides querying capaibilites but also is able to compress the logs itself.
- Part 3: Log file compression with Zstandard VFS in SQLite + benchmark
The third part dives deeper into compression capabilities of SQLite using Zstandard compression algorithm.
- Part 4: Log file compression with Zstandard selective column in SQLite
The fourth part explores database level compression of specific columns within SQLite.
You can find the script that was used to seed the database with data, perform compression and run benchmarks here.
Optimizing log storage costs
Optimizing log storage costs has become a critical concern for organizations as the volume of log data continues to grow exponentially. With the increasing reliance on cloud-based logging solutions, many companies are facing significant financial pressures due to the high costs associated with storing and managing vast amounts of log data.
These expenses can quickly spiral out of control, especially for businesses dealing with large-scale applications or those subject to stringent compliance requirements. As a result, there's a growing motivation to explore open-source tools for log compression as a means to reduce and cut costs associated with cloud logging tools.
These open-source solutions offer the potential to significantly decrease storage requirements without sacrificing the integrity or accessibility of crucial log data. By implementing effective compression techniques, organizations can not only lower their cloud storage expenses but also improve log management efficiency, enabling them to retain valuable historical data for longer periods without breaking the bank.
This shift towards cost-effective, open-source log compression tools represents a strategic move for businesses looking to optimize their IT budgets while maintaining robust logging practices.
Finding a solution
As a part of building LogdyPro we had to conduct a research of the effectiveness of log files compression techniques. This is in order to draw a baseline of what is possible out-of-the box with the open source widely available tools.
Log structure
I'm going to start by describing our sample log file. We've used an example of a webserver to generate log lines that contain variable data. A sample line of generated log in JSON format:
json
{
"time_local":"2024-08-02T15:07:24+02:00",
"remote_addr":"181.75.205.70",
"request":"DELETE https://huntercasper.london HTTP/1.1",
"status":500,
"body_bytes_sent":9469,
"http_referer":"https://google.com",
"http_user_agent":"Mozilla/5.0 (Linux; Android 11; DN2101) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Mobile Safari/537.36",
"request_time":"1.828",
"upstream_response_time":"1.857",
"upstream_addr":"1.15.54.68",
"upstream_status":500
}Generating a file that contain 1 000 000 lines took almost 14 seconds and created a file weighting 412 megabytes.
bash
$ time go run main.go
go run main.go 13.96s user 2.15s system 94% cpu 17.000 total
$ ls -h
412M access_log.jsonOK, so we have a baseline, if your system produces JSON logs and sends them to a cloud logging solution we can approximately expect to fit around 2-2.5 million lines within 1 gigabyte of JSON data sent.
Flattening JSON file to a raw lines
Immediately, we can think of one optimization - flattening the json file to get rid of property names which should drastically reduce the size of the file.
Let's quickly run a transformation via Golang script:
bash
# running a script to transform JSON to a flat file
$ go run main.go 4.05s user 1.89s system 89% cpu 6.646 totalA sample line of a JSON line mapped to a pipe (|) delimited string looks like this:
json
2024-08-02T15:07:24+02:00|181.75.205.70|DELETE https://huntercasper.london HTTP/1.1|500|9469|https://google.com|Mozilla/5.0 (Linux; Android 11; DN2101) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Mobile Safari/537.36|1.828|1.857|1.15.54.68|500After mapping the data, we achieved 44% reduction in terms of space.
bash
$ ls -h
412M access_log.json
232M access_log.txtWe already shaved almost 50% of size, which is not a bad result, however querying such file is not easy. We can use grep/awk however it's not the easiest. On the other hand, when querying JSON we can leverage CLI tools like jq however, this tool cannot leverage any kind of indexing so each time we'll have to do a full scan of the file (and parse). It may be enough for smaller files like the one above, but when you're dealing with terabytes of logs, this is unacceptable.
Let's see how well compressible those logs files are.
Compressing log file with Gzip
What is Gzip?
Gzip is a file compression tool that reduces the size of files, making them faster to transfer and easier to store. It uses the DEFLATE algorithm, combining LZ77 and Huffman coding, and is commonly used in web servers to compress files before sending them to browsers.
We're using the default settings for Gzip.
bash
$ time gzip -k access_log.json
gzip -k access_log.json 5.63s user 0.07s system 98% cpu 5.762 total
$ time gzip -k access_log.txt
gzip -k access_log.txt 5.37s user 0.05s system 98% cpu 5.524 totalbash
$ ls -lh
69M access_log.json.gz
58M access_log.txt.gzNice, we achieved pretty good result. The reason compressing JSON got so close to compressing raw text file is because the compression algorithm is able to effectively deduplicate and compress property names and JSON syntax overhead ({}[]":, characters)
As a benchmark, we wanted to try one another compression algorithm: Zstandard.
Compressing log file with Zstandard
What is Zstandard?
Zstandard (Zstd) is a fast, lossless compression algorithm developed by Facebook. It offers high compression ratios and speed, making it efficient for reducing file sizes while minimizing performance overhead.
For this compression, we tweaked the setting a little bit. Particularly we choosed the highest compression ratio and a usage of all of the CPU cores to speed up the process.
bash
# compressing json lines, zstd using all available CPU cores
$ time zstd -19 -T0 --keep access_log.json
access_log.json : 8.35% ( 412 MiB => 34.4 MiB, access_log.json.zst)
zstd -19 -T0 --keep access_log.json 315.37s user 1.96s system 581% cpu 54.550 total
# compressing raw text file, zstd using all available CPU cores
$ time zstd -19 -T0 --keep access_log.txt
access_log.txt : 13.87% ( 232 MiB => 32.1 MiB, access_log.txt.zst)
zstd -19 -T0 --keep access_log.txt 218.24s user 1.38s system 620% cpu 35.419 totalAfter all of these steps we ended up with the following files:
bash
$ ls -lh
412M access_log.json
69M access_log.json.gz
34M access_log.json.zst
232M access_log.txt
58M access_log.txt.gz
32M access_log.txt.zstHere are the results plotted on a chart.
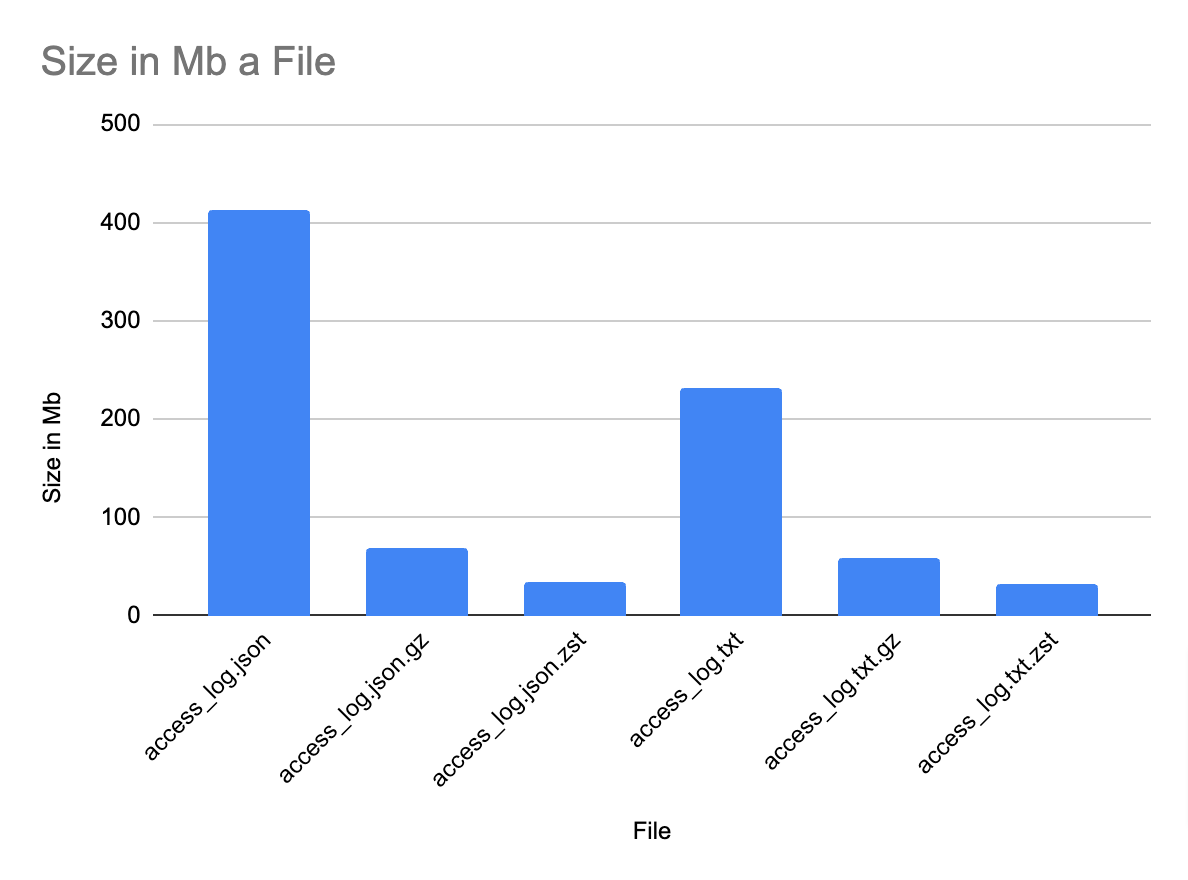
As you can see, the Zstandard achieved the best results, followed by Gzip. What's more interesting is that Zstandard achived almost the same compression level with JSON as for a raw text file, taking into account that the initial file was 412Mb, that translates to 92% (!) reduction in size. This underlines a really good quality of Zstandard compression algorithm which is able to reduce the size of repeatable JSON property names and it's syntax as well as variable strings (user-agent property in each line which takes up the most space).
Compressing big log files using Gzip and Zstandard
I repeated the same steps with 10M lines logs, and got the following results. As you can see the sizes scaled pretty much linearly along with compression.
bash
4.0G access_log_10M.json
688M access_log_10M.json.gz
344M access_log_10M.json.zst
2.3G access_log_10M.txt
582M access_log_10M.txt.gz
322M access_log_10M.txt.zstConclusion
We already found out that reducing logs can yield pretty good results using open-source compression algorithms. The culprit is that there is no easy way to query those compressed files without decompressing them and that poses a few problems:
- You need to have enough of spare space to accomodate for the uncompressed files.
- It takes time to decompress the files, and that time doesn't even account for searching through it, meaning the query times will be impacted a lot.
- In order to mitigate the above two, you could think that there could be a way to decompress only a portion of the file. And you're right, it's not impossible and actually Zstandard implements a way to "seek" through the compressed file. However it's not very practical since you need to know excatly where to look for the data you are interested in.
On the other hand, searching through compressed files requires special compression techniques that are not widely available so we're going to leave it out of the scope for this series.
In the next part of the series, we're going to explore a SQLite as a way to have both: compression and queryability.
Watch out! You're reading a series of articles
- (currently reading) Part 1: Log file compression with Gzip and Zstandard + benchmark
This is the first part of a series of articles diving into log files compression techniques.
- Part 2: Log file compression with SQLite + benchmark
The second part utilizes SQLite as an embeddable storage that not only provides querying capaibilites but also is able to compress the logs itself.
- Part 3: Log file compression with Zstandard VFS in SQLite + benchmark
The third part dives deeper into compression capabilities of SQLite using Zstandard compression algorithm.
- Part 4: Log file compression with Zstandard selective column in SQLite
The fourth part explores database level compression of specific columns within SQLite.
You can find the script that was used to seed the database with data, perform compression and run benchmarks here.