Facets, search bar and time filtering
Facets
A faceted filter, also known as faceted search or faceted navigation, is a user interface design element commonly used in information retrieval systems, databases, and online platforms to enhance search and exploration. It allows users to narrow down search results or browse content by applying multiple filters simultaneously.
Facet filter is autogenerated and using them is instant.
Searchbar query
Searchbar query allows you to provide a human readable query and filter the data set in a semantic way. Read more in the chapter.
Timeframe limit
You are able to limit the displayed log entries by time with a second precision.
INFO
To better illustrate the logic behind filtering in conjunction, you can imagine specific filtering capabilities to be working the following:
(selected facets) AND (searchbar query) AND (timeframe limit)
This means, each filtering factor will limit the output data set and they all work together in exclusive way.
Producing facets
Each log line can produce multiple facates that will be used to generate automatic filters
ts
(line: Message): CellHandler => {
return {
text: line.json_content.method,
facets: [
{ name: "Method", value: line.json_content.method }
]
}
}An example code containing a single facet produced based on method field in the json_content. Because you're using code to generate facets, you can use bespoke logic to decide when and what values to generate.
The below example presents a custom logic for producing a facet value.
ts
(line: Message): CellHandler => {
facets = []
if(line.json_content.method.includes('foo')){
facets.push({ name: "Method", value: line.json_content.method })
}
return {
text: line.json_content.method,
facets: facets
}
}Automatic filters
Filters in the left column are generated automatically based on the Facets produced for each line. Below you can see in the screenshot selected values for different facets.
Faceted column
Since a lot of times you will end up writing repetitive code that produces a facet like this:
ts
(line: Message): CellHandler => {
return {
text: line.json_content.method,
facets: [
{ name: "Method", value: line.json_content.method }
]
}
}We've added faceted option to a column. Enabling it will work exactly the same as the above code, except that you don't have to write it so it takes a blink of an eye to enable facets for multiple columns as presented below.
Facet filtering logic
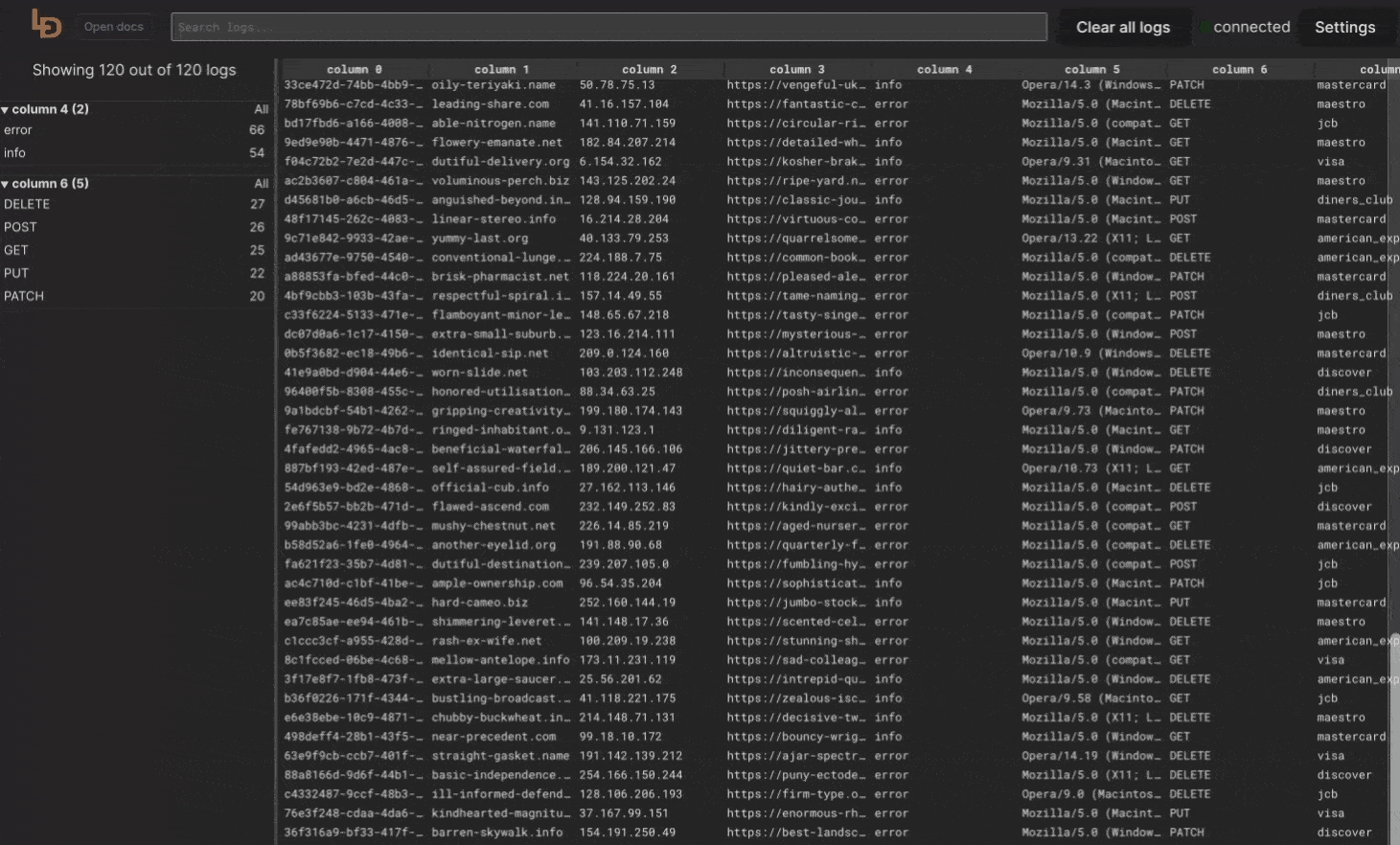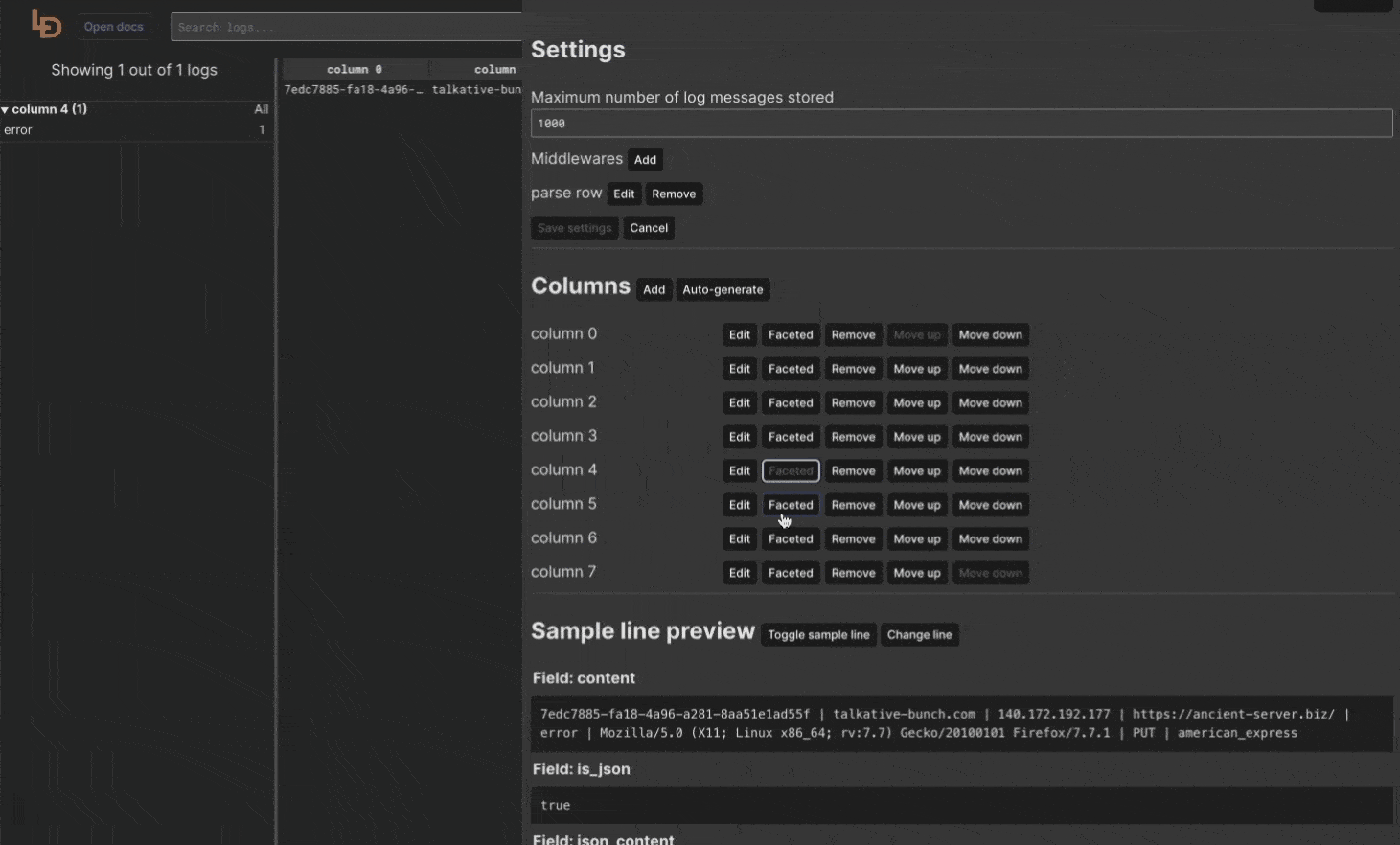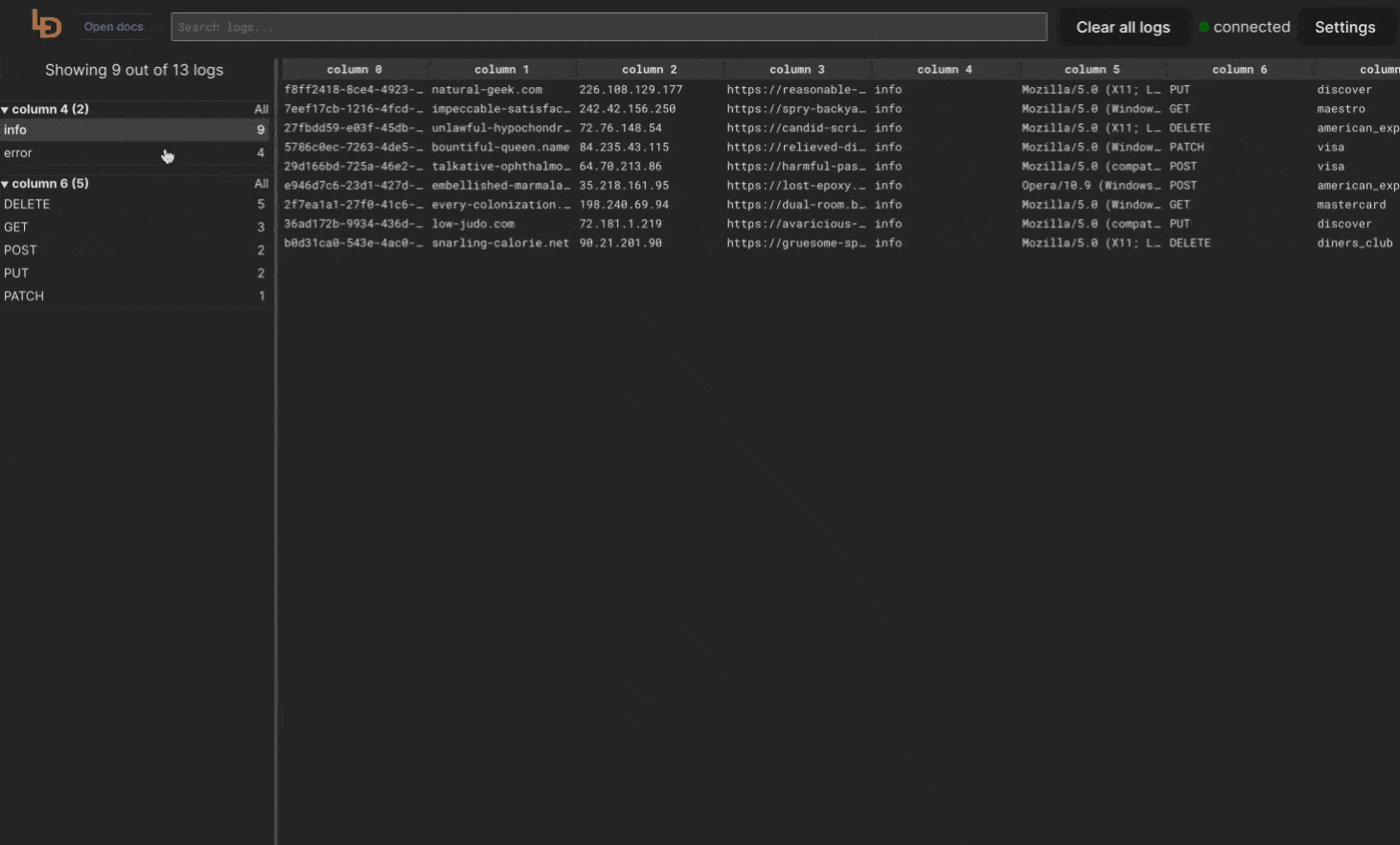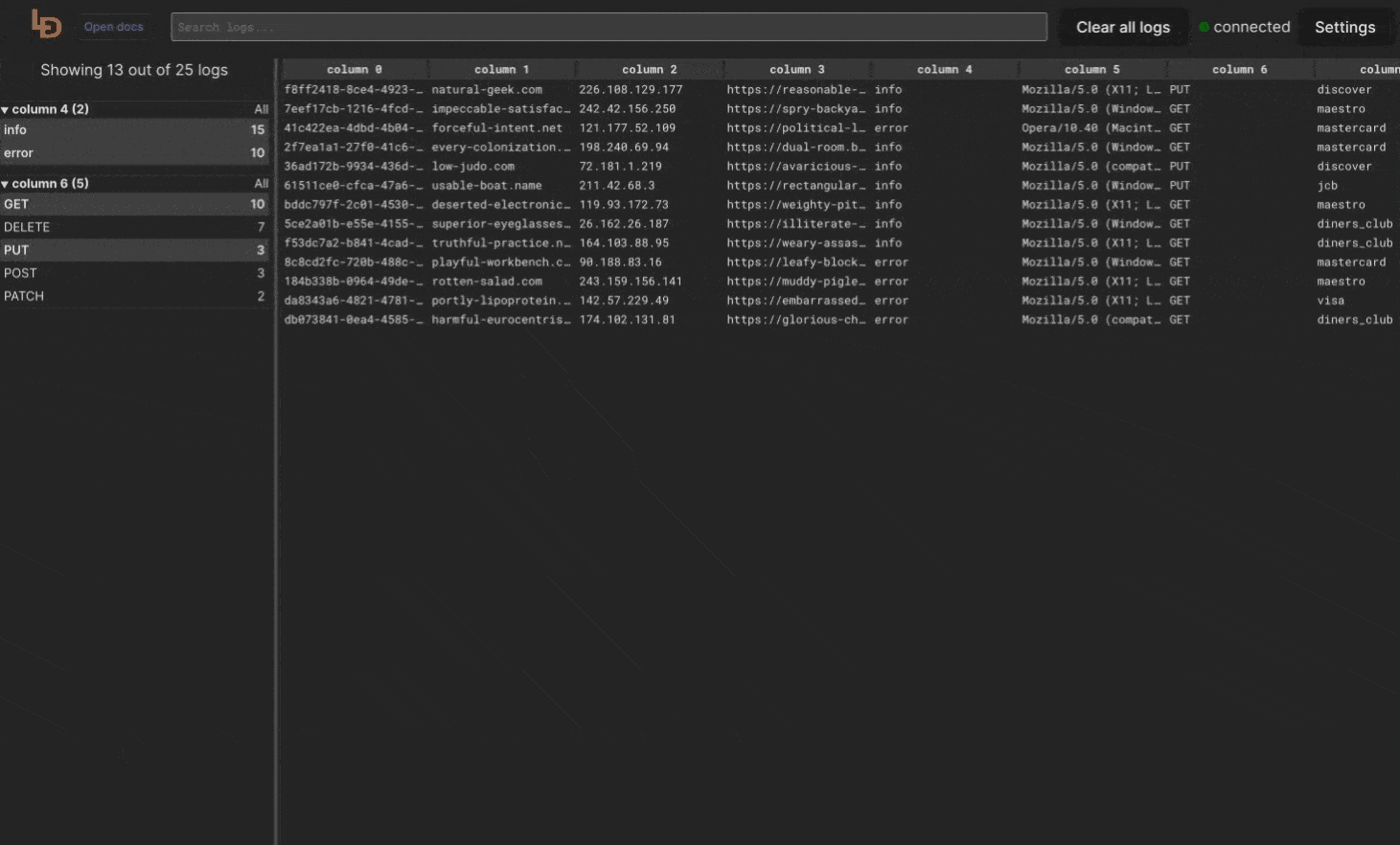
When selecting facets from multiple groups, the logic used will select rows that meet ALL of the selected values. However for values selected within a single facet, the rows that meet ANY of the values will be selected.
To better illustrate the example. For the above screenshort the filtering logic will look like
Method == POST AND Level == error AND Issuer == disoverHowever, if you select and additional value from Level facets, then the logic will turn into
Method == POST AND (Level == error OR Level == info) AND Issuer == disoverSemantic filtering via searchbar
As a part of LogdyPro development, we have developed our own expression syntax that is used to filter structured log entries. This syntax is called Breser.
Since the beginning we were wondering how we can make it a part of the open-source version of Logdy. Since version 0.14 we're embedding a WebAssembly compiled version of Breser into Logdy release. That means, out users will be shipped with a fully functional capabilities of semantic filtering.
Breser
Read Breser docs for more information.
Take a look at example queries that are possible with this new functionality.
js
// a typical Breser query
data.domain contains "org" and data.ipv4 ends "119"
// a more advanced query
data.age > 30 or (data.color in ("yellow", "green") and data.height > 0)
// you can run a query on a raw (non JSON content)
raw includes "lorem ipsum"Below is a screenshot presenting an example query and a filtered data set:
The prerequisite is that you currently have a couple of top-level fields at your disposal in the query:
js
// raw - contains a raw log line, you can use full text search query on it
example: raw includes "lorem ipsum"
// match a regex (email) on a raw content
example: raw match "`^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$`"
// data - represents a parsed log line. You can use nested fields.
example: data.field == "foo bar"
// ts - holds a unix millisecond timestamp
example: ts > 123456789 and ts < 12354567
//origin - holds an origin object (see: https://logdy.dev/docs/reference/code)
example: origin.file == "file.foo" or origin.port == "9080"WARNING
Semantic filtering works in conjunction with facets. That means the result set will be first filtered by selected facets then a query.
Full text search
As of version 0.14 full text search capability can be achieved by constructing a query in the following way:
js
// you can run a query on a raw (non JSON content)
raw includes "lorem ipsum"
raw match "golang format regex goes here"For more information refer to Breser docs.
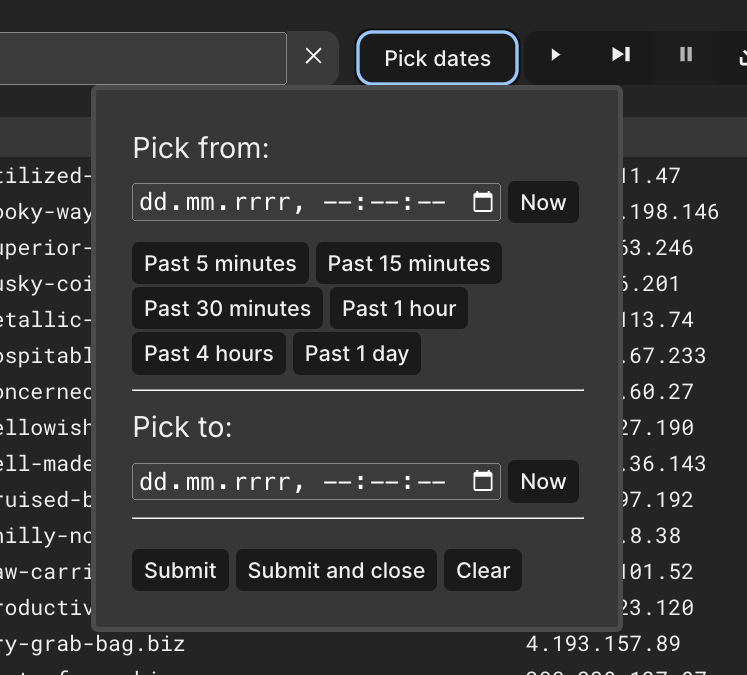
Date and time filtering
You can limit the output data set by using time filters with a few predefined presets.
Important note! Which field is used to filter log entries?
The field of the log entry appearing in the buffer is currently taken into account. That means, if you read a file into memory, the lines will be timestamped with the time they got into the buffer.
It's possible to overcome this issue by overwriting the timestamp (ts field) in a middleware.
ts
(line: Message): Message | void => {
// each log line contains ISO date eg. { "date": "2024-12-13T22:03:06.679Z" }
line.ts = new Date(line.json_content['date']).getTime()
return line;
}The above middleware, if added will replace the incoming timestamp (Unix milliseconds) with a timestamp parsed from a log entry.
Here's a screenshot presenting a date/time picker for the timeframe.
Correlation IDs
Logdy can automatically filter log messages that are correlated by the same ID (read more on our blog post). Simply assign a correlation_id field in a middleware for each received log message.
Let's suppose your log messages contain a requestId that holds a random string and that value will be assigned to all of the log messages produced during a particular request lifecycle or a user transaction.
json
{
"requestId": "UmAdplHI",
"ts": "19:40:37.3196",
"uuid": "6b46d8b6-8f2b-4bba-bfa8-85b2cc9a85c9",
"message": "action successful"
// more fields...
}INFO
Keep in mind that the request (or a transaction) can span across multiple modules, services or even remote machines. These can produce logs in different formats, however, one thing in common should be that they all pass the requestId between each other. This is critical for later correlation of these log messages in a centralized logs viewer.
Since it's a JSON format, Logdy supports it naturally, so now you can setup a simple middleware that will assign a correlation_id from a log message.
ts
(line: Message): Message | void => {
// Simple assignment if all of the logs share the same format
line.correlation_id = line.json_content.requestId
// You can assign `correlation_id` from different formats
let jc = line.json_content
line.correlation_id = jc.requestId || jc['x-correlation-id'] || jc.reqUuid
return line;
}Next, open a specific log message. If the correlation_id has a value assigned, a button Display correlated lines will be active. Clicking it, will filter all of the visible rows to only the ones that share the same correlation_id.
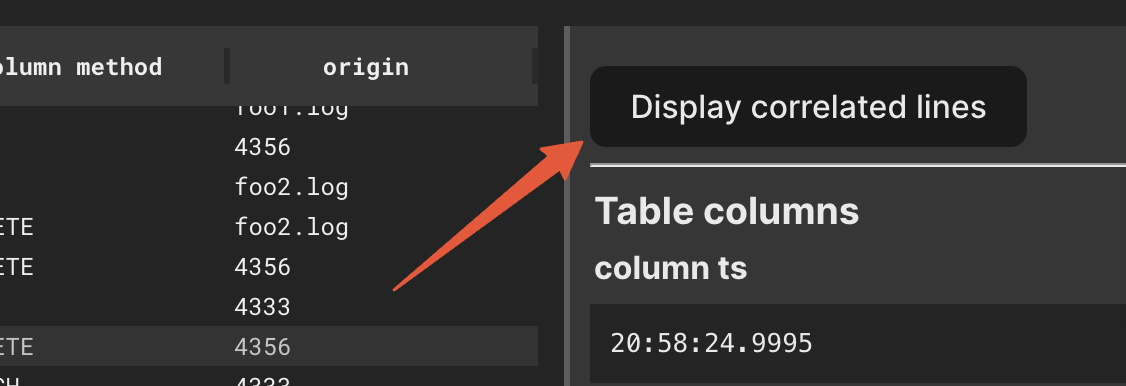
TIP
Keep in mind that current filters and facets will still be applied after you activate filter on correlated log messages.